12月22日消息,阿里开源了全新的图像生成模型Qwen-Image-Layered,该模型首次在内部实现了PS级别的图层理解与图像生成功能。
千问新模型运用自主研发的创新架构,能够把图片“分解”为多个图层,如同专业设计师借助Photoshop进行分层作图与修图一般,可达成近乎“零偏移”的AI图像精准编辑,从根本上AI生图的一致性问题,推动大模型在专业设计领域的实际应用落地进程。
Qwen-Image-Layered突破了主流视觉大模型的“扁平式思维”局限,借助“分层解析”与“信息补全”的方式,构建起对现实世界更精准的“物理性认知”,推动AI从简单的平面“图像描述”进阶到对真实场景的“空间重构”能力。

在当下的视觉大模型领域里,图像一致性编辑一直是个核心难题。AI生成图像富有创意却难以进行编辑,关键原因在于大模型对图片的理解是平面化的,只是把一堆像素点紧密地联结在一起,无法像人类那样感知到图像中物体的远近、遮挡等物理层面的关系。
因此,让大模型进行图像生成与编辑就如同抽卡“开盲盒”一般:举个例子,当你希望把画中的猫向左移动10厘米时,AI根本不清楚猫左移后空出的背景区域该呈现什么内容,只能重新生成一次图像,结果往往是猫和背景都变得面目全非。
这种“牵一发而动全身”的随机性,使得AI绘图在商业广告设计、UI界面设计、影视后期处理等对精准度要求极高的专业领域,始终只能充当参考角色,难以真正替代专业工具。
Qwen-Image-Layered 的问世,标志着视觉大模型的核心逻辑从“像素预测”过渡到“结构重组”。千问团队自主研发了全新的RGBA-VAE编码技术,在传统RGB图像基础上加入承载透明度信息的“Alpha通道”,使模型具备了对图层的认知能力。
同时新模型采用了创新的VLD-MMDiT架构,配合独特的“图层级3D位置编码”,让AI自动“脑补”被遮挡部分的背景纹理,实现对图层和空间的更深入理解和生成。
据了解,为训练这种能力,千问团队从海量的专业Photoshop(PSD)文件中提取真实图层逻辑,让AI从出生起就拥有专业设计师的“分层思维”。
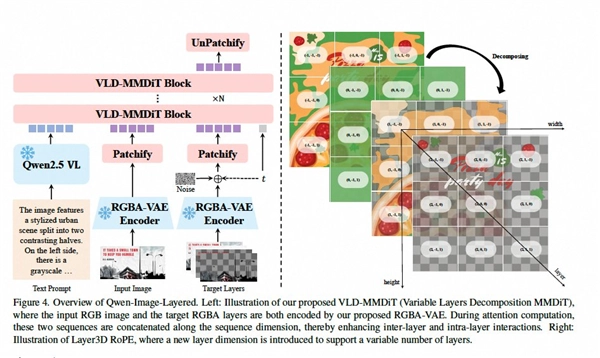
Qwen-Image-Layered模型架构图
业内人士指出,千问新模型将为创意产业带来实质性变革。AI生图不再是死板一块,而成为一个活生生的、可无限调整的素材库。
图片编辑无需再依赖复杂精细的人工抠图,AI已原生具备“内在可编辑性”。设计师、动画及影视制作人员能够在确保背景或主体完全不变的情况下,对特定图层的构件进行位移、缩放或重绘操作,从而大幅提高数字内容创作的生产效率。
据了解,Qwen-Image-Layered已在魔搭社区和HuggingFace开源,开发者和企业可免费下载商用。
截至目前,阿里巴巴已开源近400个千问系列模型,相关模型的全球累计下载量已突破7亿次,由其衍生出的模型数量超过18万个,在开源模型领域位居全球首位。而通义大模型目前已服务超100万家客户,在中国企业级大模型的调用市场中,通义大模型的市场份额排名第一,成为中国企业选用最多的大模型产品。