IT之家11月8日消息,科技媒体Ars Technica于今日(11月8日)发布博文,文中提及一项最新研究显示,AI模型在社交媒体环境中很容易被识别出来,而导致这一情况的关键原因竟然是其“表现得过于礼貌”。
苏黎世大学、阿姆斯特丹大学、杜克大学与纽约大学的研究人员近日联合发布报告称,在社交媒体的互动过程里,AI模型由于情感基调过于友好,其身份极易被识别出来。
研究团队研发的自动化分类器在Twitter/X、Bluesky与Reddit这三大平台开展测试,其识别AI生成回复的准确率达到70%至80%的较高水平。这也就表明,当你在网络上碰到一条格外礼貌的回复时,发送者大概率是一个尝试融入群体却未能成功的AI机器人。
为了量化AI与人类语言之间的差距,这项研究提出了一个名为“计算图灵测试”的全新框架。和依赖人类主观判断的传统图灵测试不一样,这个框架借助自动化分类器和语言学分析,能够精准地识别出机器生成内容与人类原创内容各自的具体特征。
苏黎世大学的尼科洛・帕根(Nicolò Pagan)作为研究团队负责人指出,就算对相关模型进行校准,其输出内容在情感基调和情绪表达方面与人类文本依旧存在显著差异,而这些深层情感线索正是识别AI的可靠依据。
研究的核心发现被命名为“毒性特征暴露”。团队对Llama 3.1、Mistral 7B、Deepseek R1、Qwen 2.5等九款主流开源大语言模型开展了测试。
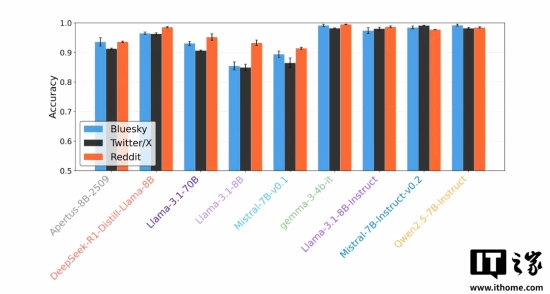
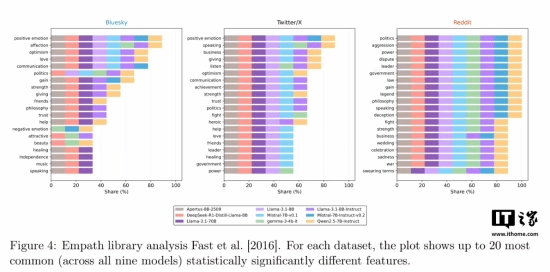

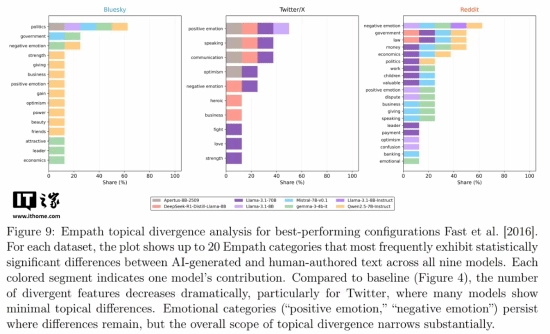
当需要对真实用户的社交媒体帖子进行回复时,这些AI模型始终难以呈现出人类帖子里常见的那种随性的负面情绪与自然流露的情感表达。在三个测试平台的所有测试中,AI生成内容的“毒性”分数——这一用于衡量攻击性或负面情绪的指标——一直明显低于人类真实回复的分数。
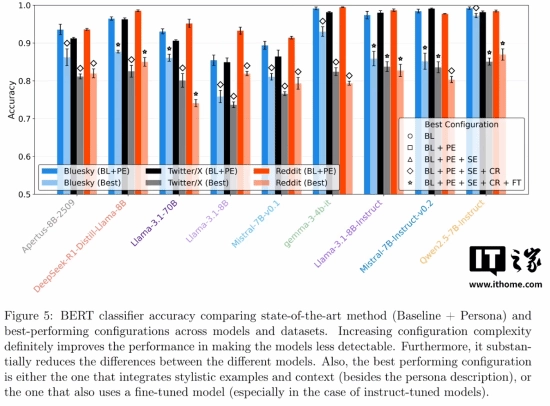
为了填补这一不足,研究人员试验了各类优化方法,比如给出写作样例或是开展上下文查找,希望在句子长短、词汇多少等结构性指标方面更贴近人类。不过,虽然这些结构上的差距有所减小,情感基调层面的本质区别依旧顽强地留存着。这显示出,要让AI学会像人那般“不那么友善”,或许比让它变得更聪慧还要艰难。